“Indexed, although blocked via robots.Txt” indicates that Google indexed URLs despite the fact that they have been blocked via your robots.txt file.
Robots.Txt in short
A robots.Txt file carries directives for search engines like google and yahoo. You can use it to save you search engines from crawling precise elements of your website and to offer serps helpful pointers on how they can pleasant crawl your internet site. The robots.Txt document plays a massive position in SEO.
When implementing robots.Txt, preserve the following first-rate practices in mind:
- Be cautious when making changes in your robots.Txt: this document has the capacity to make large components of your website inaccessible for serps.
- The robots.Txt file need to reside within the root of your website (e.G. Http://www.Example.Com/robots.Txt).
- The robots.Txt record is simplest legitimate for the overall domain it resides on, including the protocol (http or https).
- Different search engines interpret directives differently. By default, the first matching directive continually wins. But, with Google and Bing, specificity wins.
- Avoid the use of the crawl–postpone directive for search engines as much as possible.
Google has marked these URLs as “Valid with warning” due to the fact they’re uncertain whether or not you want to have those URLs listed. In this article you’ll learn how to restore this issue.
Here’s what this looks like in Google Search Console’s Index Coverage report, with the quantity of URL impressions shown:
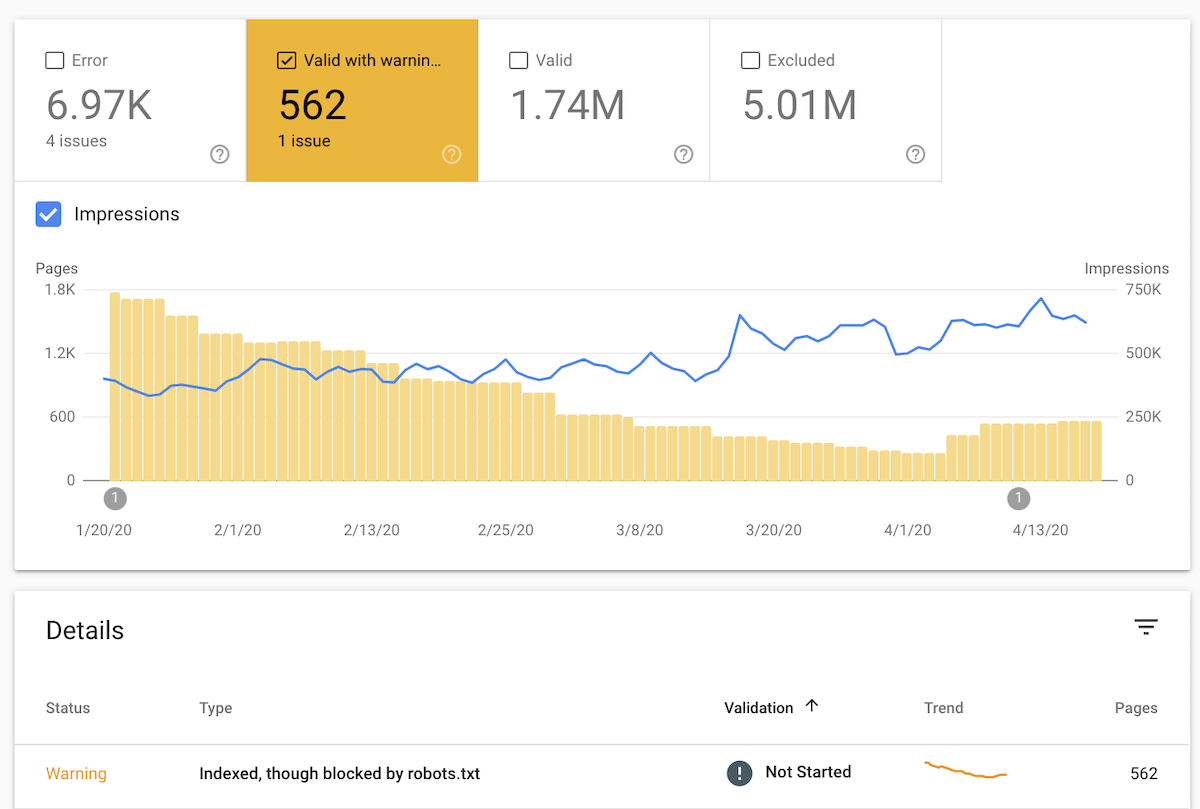
Normally, Google wouldn’t have indexed these URLs but seemingly they discovered links to them and deemed them important enough to be indexed.
It’s possibly that the snippets which can be shown are suboptimal, similar to:
How to restore “Indexed, though blocked with the aid of robots.Txt”
- Export the listing of URLs from Google Search Console and type them alphabetically.
- Go through the URLs and check if it consists of URLs:
- That you need to have indexed. If this is the case, replace your robots.Txt file to permit Google to get admission to these URLs.
- That you don’t want serps to get admission to. If this is the case, depart your robots.Txt as-is however check if you’ve were given any inner hyperlinks which you have to remove.
- That search engines like google and yahoo can get admission to, however which you don’t need to have listed. In this case, replace your robots.Txt to reflect this and practice robots noindex directives.
- That shouldn’t be on hand to anyone, ever. Take for example, a staging environment. In this case, follow the stairs explained in our Protecting Staging Environments article.
- In case it’s no longer clear to you what a part of your robots.Txt is causing these URLs to be blocked, pick an URL and hit the TEST ROBOTS.TXT BLOCKING button in the pane that opens on the right hand side. This will open up a brand new window displaying you what line for your robots.Txt prevents Google from getting access to the URL.
- When you’re carried out making changes, hit the VALIDATE FIX button to request Google to re-evaluate your robots.Txt towards your URLs.